Follow
FollowVon Daniel Kirsch und Julius Tröger
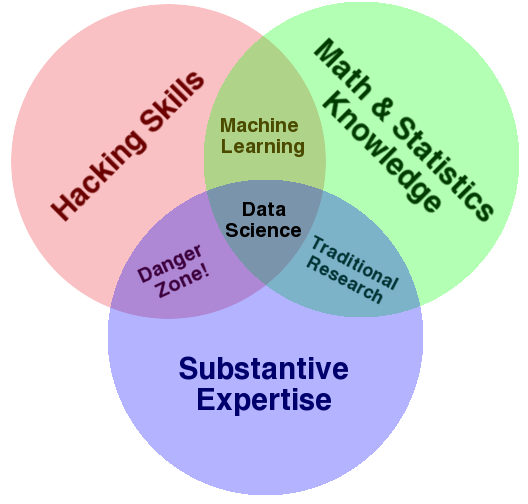
Der digitale Werkzeugkasten für (Daten-)journalisten erweitert sich ständig. Nicht fehlen sollten darin die Grundlagen von Machine Learning. Dabei handelt es sich um einen Überbegriff für Algorithmen, die als Sparringspartner in der Datenanalyse eingesetzt werden können und mit deren Hilfe bereits einige Geschichten entstanden sind. Dieser Blogbeitrag zeigt anhand von vielen Praxisbeispielen, wie Decision Trees, Neuronale Netze und Co. Journalisten nützlich sein können.
Was ist Machine Learning?
Machine Learning gibt es schon seit vielen Jahrzehnten. Mit der steigenden Verfügbarkeit von Daten und Rechenpower, bekommt das Thema aber immer mehr Aufmerksamkeit.

Beim Machine Learning wählt man einen Algorithmus und übergibt ihm möglichst viele Trainingsdaten. Der Rechner erkennt darin selbständig Muster und Gesetzmäßigkeiten und erstellt ein Modell, mit dem er auch Daten beurteilen kann, die er nie zuvor gesehen hat.
Es gibt Hunderte kostenlose Online-Ressourcen für den Einstieg in Machine Learning. Vor allem die Kurse bei Coursera und Udacity oder der Podcast „Machine Learning Guide“ sind zu empfehlen. Auch die Blogbeiträge “A Non-Technical Introduction to Machine Learning” und “Machine Learning is Fun” lohnen sich. Um keine Neuigkeiten zu verpassen und um sich inspirieren zu lassen, kann man die Newsletter DataScienceWeekly, DataMachina, PocketCluster und Artificial Informer abonnieren.
Der einfachste Algorithmus ist die Lineare Regression, sozusagen das „Hello World“ des Machine Learning. Damit kann man prüfen, ob sich eine Variable durch eine oder mehrere andere Variablen erklären lässt, z.B. Je höher die Kaufkraft, desto mehr Ärzte gibt es. Dieses sehr einfache Modell kommt mit lediglich zwei Parametern aus: Die Steigung und der Achsenabschnitt einer Geraden.
Im Gegensatz dazu können Neuronale Netze statistische Modelle mit bis zu mehreren hundert Millionen Parametern erstellen. So können mittels Deep Learning Daten, die von einem Computer sonst kaum interpretierbar sind – wie etwa Texte, Fotos und sogar Videos datenjournalistisch verarbeitet werden.

Zwischen diesen beiden Extremfällen existieren Dutzende Machine-Learning-Algorithmen für verschiedene Anwendungsfälle. In der Praxis sind für Journalisten derzeit aber nur eine Handvoll für spezifische Anwendungsfälle interessant. Die wichtigsten Konzepte werden nun erklärt und anhand von datenjournalistischen Beispielen verdeutlicht.
Muster und Ausreißer finden mit Unsupervised Learning
Oft muss man sich zu Beginn eines Projekts erst einmal einen Überblick über den Datensatz verschaffen: Wie sind die Min-, Max-, Medianwerte. Und: Lassen sich Trends, Muster oder Ausreißer entdecken? Bei letzterem helfen unsupervised (unüberwachte) Machine-Learning-Algorithmen. Diese lernen von den Strukturen in den Daten und helfen bei der explorativen Erkundung.
Dimensionsreduktion
Häufig haben Datensätze sehr viele Spalten. Welche Datenpunkte sind Ausreißer? Welche Datenpunkte ähneln sich? Während man Daten aus zwei Spalten schnell in einem Scatterplot visualisieren kann, ist das bei sehr vielen Spalten nicht mehr möglich. Mit der Technik der Dimensionsreduktion können aber viele Daten in einer zweidimensionalen Ebene visualisiert werden.
Gängige Algorithmen: Multi Dimensional Scaling, Locality Sensitive Hashing, Principal Component Analysis, t-sne, Autoencoder
Ein Beispiel für Dimensionsreduktion zeigt das Projekt Wahlland von Zeit Online. Dort wurden Wahlkreise nach Ähnlichkeit im Wahlverhalten mit Hilfe des Algorithmus Multi Dimensional Scaling visualisiert.

Ein weiteres Beispiel: Journalisten von California Watch haben Gesetzestexte mit Hilfe des Algorithmus Locality Sensitive Hashing verglichen und so aufgedeckt, wie aufeinander folgende Gesetzgeber voneinander abgeschrieben haben. Die Dimensionsreduzierung hilft hier dabei, ähnliche Textpassagen sehr schnell finden zu können.

Clustering
Die andere wichtige Kategorie unüberwachter Algorithmen ist Clustering, das Gruppieren von ähnlichen Datenpunkten.
Gängige Algorithmen: K-Means, DBSCAN, Hierarchical Clustering, Latent Dirichlet Allocation
Indem sie Community Colleges in mit dem DBSCAN-Algorithmus Gruppen mit maximaler Entfernung von 20 Meilen einteilten, konnten Journalisten von California Watch zeigen, wie viel der Staat sparen könnte, wenn für diese eine gemeinsame Verwaltung durchgesetzt würde.

Ein weiteres Einsatzfeld von Clustering ist das sogenannte Topic Modeling, das thematische Clustering von Text-Dokumenten. So konnte die NZZ mit Hilfe des Algorithmus Latent Dirichlet Allocation alle Artikel eines Jahres in Themenblöcke clustern und visualisieren.

Klassen und Zahlen vorhersagen mit Supervised Learning
Für Supervised Learning benötigt man, anders als beim Unsupervised Learning, annotierte Trainingsdaten. Das heißt, wenn man einen Datensatz besitzt, bei dem man eine Eigenschaft (z.B. das Einkommen bei Personen) kennt, so kann man versuchen einen Algorithmus zu trainieren, der aus anderen Eigenschaften der Datenpunkte (z.B. den Beruf, Wohnort, Alter), Regeln ableitet, um das Einkommen vorherzusagen. Mit dieser Technik lassen sich mit unterschiedlichen Algorithmen sowohl Zahlen, als auch Klassen vorhersagen. Zwar müssen Journalisten oft selbst aufwendige Handarbeit leisten, um Trainingsdatensätze zu schaffen. Dennoch helfen Algorithmen ungemein bei der Recherche, wie die folgenden, bereits veröffentlichten Beispiele zeigen.
Gängige Algorithmen: Lineare Regression, Logistische Regression, Naive Bayes, Nearest Neighbors, Decision Tree, Random Forest, Support Vector Machine, Neuronales Netz
Klassen vorhersagen
Journalisten von The Atlanta Journal-Constitution klassifizierten mithilfe einer logistischen Regression rund 100.000 Disziplinarverfahren gegen Ärzte, und konnten so automatisiert filtern, ob es sich bei der jeweiligen Tat um einen sexuellen Übergriff handelt. Sie mussten “nur” noch 6000 Dokumente lesen – und konnten so nachweisen, dass sexuelle Übergriffe von Ärzten in den USA kaum geahndet werden.

Ebenfalls mittel logistischer Regression konnte das Recherchebüro Propublica Risikobewertungen von rund 18.000 Straftätern mit deren wirklichen Strafregistern vergleichen – und so das sogenannte COMPAS-System teilweise reverse engineeren. Die Journalisten konnten so nachweisen, dass Risikoklassen zur Rückfallquote schwarze Straftäter benachteiligen.

Die Polizei von Los Angeles veröffentlichte fehlerhafte Kriminalitätsstatistiken. Die LA Times konnte nachweisen, dass schwere Straftaten in internen Berichten fälschlicherweise als geringfügige eingestuft wurden. Die Journalisten gingen 20.000 der rund 100.000 Datensätze manuell durch und nutzten diese als Trainingsdaten. Mit Hilfe eines Algorithmus namens Support Vector Machine konnten sie dann die Restlichen automatisiert klassifizieren.

Weniger investigativ haben Journalisten von The Atlantic Machine Learning eingesetzt. Mit Trump-or-Not-Bot haben sie einen Twitter-Bot erstellt, der mittels Naive-Bayes-Algorithmus die Wahrscheinlichkeit berechnet, ob Donald Trump persönlich oder sein Team getwittert hat.

In all diesen Beispielen wird mit Text gearbeitet. Textklassifikation mit Machine-Learning-Algorithmen ist ein wichtiges Anwendungsfeld für Journalisten. Dabei muss beachtet werden, dass viel Arbeit in Umwandeln der natürlichen Sprache in Zahlen bzw. Vektoren gesteckt werden muss. Dafür benötigt man Techniken aus dem Bereich Natural Language Processing.
Machine Learning kann aber auch mit weiteren Mediendaten wie Foto, Audio und Video eingesetzt werden. Dafür werden heutzutage oft Neuronale Netze genutzt. Diese sind vage von der Struktur des menschlichen Gehirns inspiriert – und können durch ihre Komplexität aufwendige Klassifikationsprobleme lösen. Dafür benötigen sie aber auch besonders viele Trainingsdaten. Für Bilder werden dabei in der Regel Convolutional Neural Nets – kurz ConvNets – eingesetzt. Bei Texten oder Audiodaten kommen oft Recurrent Neural Nets (RNNs) zum Einsatz. Meistens sind diese beiden Architekturen gemeint, wenn man von Deep Learning spricht.

ConvNets können zur Bildklassifizierung eingesetzt werden
Neuronale Netze sind nicht einfach selbst aufzusetzen. Allerdings muss auch gar nicht alles selbst bauen, sondern kann auf (kostenpflichtige) APIs zurückgreifen, die Deep-Learning-Dienste bereitstellen. Microsoft zum Beispiel bietet mit den Cognitive Services Gesichts- oder Emotionserkennung an. Auch Googles Cloud Vision API oder Watson von IBM liefern ähnliche Dienste.

Ein Beispiel für den Einsatz von Neuronalen Netzen im Journalismus: The Economist nutzten die Microsoft-API, um die Emotionen von Hillary Clinton und Donald Trump während der TV-Duelle zu analysieren und zu vergleichen. Erwartungsgemäß zeigte die Auswertung, dass Trump wütender als Clinton agierte. Eine ähnliche Auswertung wird in dem Artikel „One Angry Bird“ durchgeführt.

Zwar fehlt in diesem Fall der große Erkenntnisgewinn. Dennoch ist erstaunlich, wie einfach Deep-Learning-Techniken bereits eingesetzt werden können. Wohin die Reise auch im Journalismus gehen kann, lässt sich anhand von Beispielen aus der Wissenschaft zeigen: Forscher trainierten ein Neuronales Netz, dass es den Wert von Autos auf rund 50 Millionen Streetview-Fotos identifizieren und somit soziodemographische Daten wie Alter, Bildung oder Wahlverhalten machen konnte.

Ein weiteres Beispiel: Ein Asia-Weekly-Journalist bereitete ein langes Videointerview mit einer Transgender-Aktivistin aus Nepal mit Hilfe der IBM-Api auf. Deren Natural Language Classifier arbeitet unter anderem mit Neuronalen Netzen. So können Nutzer direkt ihre Fragen per Eingabe oder Sprache stellen.

Zahlen vorhersagen
Die meisten Fragestellungen im Journalismus sind Klassifikationen. Es ist aber auch möglich, Zahlen vorherzusagen.
Die Journalisten von El Financiero haben einen interaktiven Rechner auf Basis einer multiplen linearen Regression entwickelt, der das eigene Gehalt aufgrund soziodemographischer und weiterer Daten schätzt. Es wird also eine Zahl basierend auf mehreren anderen Variablen vorhergesagt.

Interpretierbare Modelle vs. Black-Box-Algorithmen
Manchmal geht es gar nicht um die Vorhersage eines Modells, sondern um das Modell selbst. Es gibt Modelle, die interpretierbar sind, und es so ermöglichen, die Daten besser zu verstehen. Dazu gehören vor allem Decision Trees (Entscheidungsbäume).
Journalisten der New York Times zeigt beispielsweise anhand des Decision-Tree-Algorithmus, welche Faktoren zur Wahl von Clinton oder Obama führten.

Im Gegensatz dazu, lassen sich Algorithmen wie Random Forest, Support Vector Machines oder Neuronale Netze nicht interpretieren.Es handelt sich um Black Boxes – man gibt Daten rein und bekommt ein Ergebnis raus. Manche Modelle, wie tiefe Neuronale Netze haben so viele Parameter, dass es einfach nicht mehr nachvollziehbar ist, was eigentlich genau in den Parametern gespeichert ist.

Aber auch einfache, interpretierbare Modelle können mit sogenannten Ensemble-Methoden zu komplizierten Modellen zusammengesetzt werden. Das bedeutet, dass mehrere Algorithmen zusammengeschaltet und deren Ergebnisse dann (mittels sogenanntem Bagging oder Boosting) kombiniert werden. Die Modelle werden dadurch meistens genauer, allerdings auch schwieriger zu interpretieren.
Random Forest ist so ein Fall. Sehr viele Decision Trees werden gleichzeitig auf Teilmengen des Datensatzes trainiert und stimmen später über das Ergebnis ab. Technisch gesehen ist das ein of Bag of Decision Trees. Während jeder einzelne Baum interpretierbar ist, ist das ganze Konstrukt eine Black Box. Im Grunde genommen hat man immer die Wahl zwischen Interpretierbarkeit und Genauigkeit.

Wann wird wie welcher Algorithmus eingesetzt
Nach diesem ausführlichen Algorithmus-Namedropping stellt sich natürlich die Frage, wann man welchen Algorithmus einsetzt. Neben dem Anwendungsfall kommt es auch auf die Anzahl der vorhandenen Daten und die Zeit, die man für die Modellanpassung einplant, an.

Oft werden mehrere ausprobiert – und der akkurateste dann ausgewählt. Die folgende Grafik gibt eine einfache Entscheidungshilfe, wann man welchen Algorithmus einsetzen sollte.

Die exakten Funktionsweisen der Algorithmen, sowie deren mathematischer Hintergrund sprengt den Rahmen der Kurzeinführung. Zwar kommt man mit Out-of-the-Box-Lösungen und Beispiel-Code schon recht weit. Dennoch ist ein tieferes Verständnis von Linearer Algebra und Statistik nötig, um Machine Learning richtig betreiben zu können.
Für Journalisten heißt das, vor einer Veröffentlichung Experten mit ins Boot zu holen. Hilfe bei den Berechnungen erhält man zum Beispiel bei StackExchange. Wer seine Modelle und Schlussfolgerungen gegenchecken lassen möchte, kann sich auch an den IDW-Expertenmakler oder Statscheck wenden. Was bereits weitgehend im Datenjournalismus praktiziert wird, ist bei Machine Learning noch wichtiger. Rohdaten und Methodik müssen veröffentlicht werden.
Praxisbeispiel
Es gibt sehr viele Möglichkeiten, Machine-Learning-Code zu schreiben. Sehr häufig wird Python mit der Library Scikit Learn genutzt. Vielen Datenjournalisten ist die Statistiksoftware R aber geläufiger – und wird daher empfohlen, um zu experimentieren. Quasi-Standard ist das Package caret, das alle oben genannten Algorithmen automatisch lädt, wenn sie benötigt werde und die Syntax vereinheitlicht. Einen Decision Tree selbst erstellen? Hier können Skript und Daten aus dem Workshop „Machine Learning für Journalisten“ heruntergeladen werden.
Uns interessiert eure Meinung. Ist Machine Learning für Journalisten wichtig – oder ein eher zu vernachlässigendes Buzzword? Habt ihr bereits Erfahrung aus der Praxis und habt Anmerkungen zu dem Blogpost oder habt ihr einen Fehler gefunden? Wir freuen uns über Kommentare.